シティズンデータサイエンスラボ
マガジン

市民データサイエンスの現場を訪ねて

シティズンデータサイエンスラボ
- 30本
データビークルの最高製品責任者であり統計家の西内啓がデータ活用で成果をあげている企業・組織のキーパーソンの方とデータサイエンスの現実について語り合う対談シリーズ。

データサイエンス入門講座
シティズンデータサイエンスラボ
- 21本
データを活用してエビデンスに基づいた経営判断を行いたいと考えるすべての人に。「データでもっと儲ける方法 ~経営とマーケティングのためのアナリティクスデザイン~(著:西内啓/発行:翔泳社)」の全文を公開します。
最近の記事
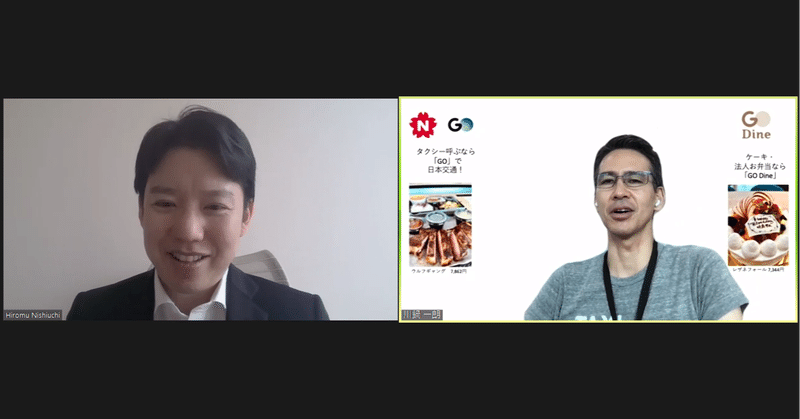
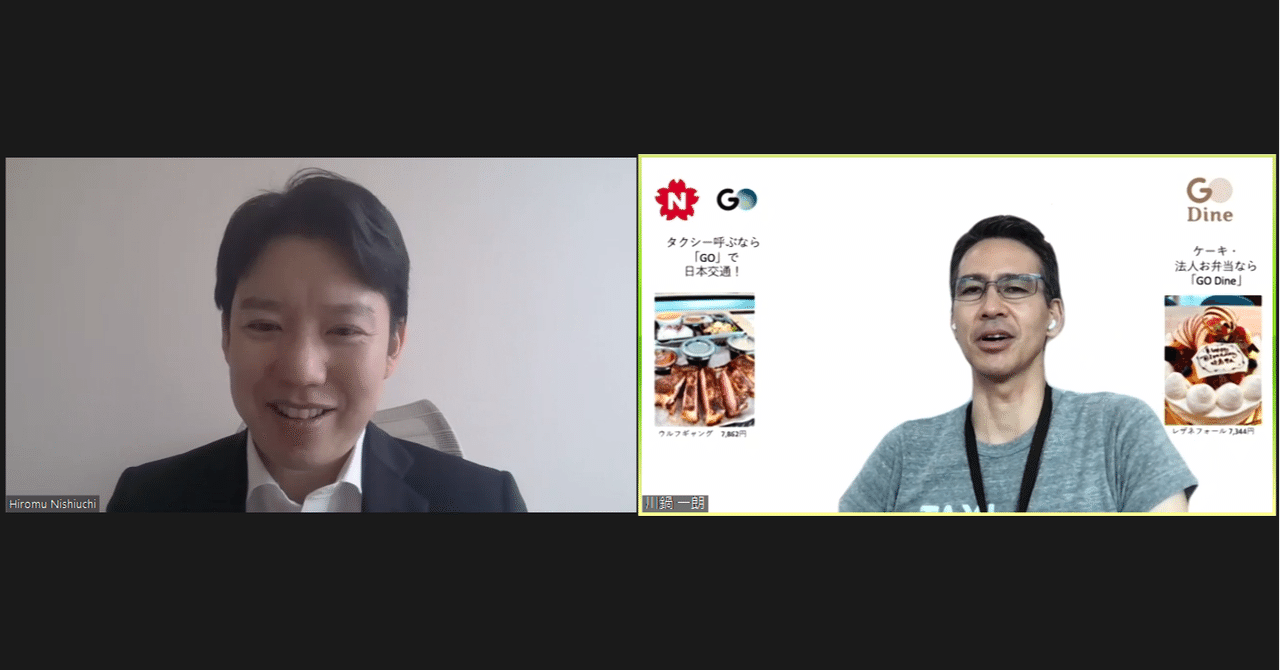
「データ活用で新しいモビリティインフラへ」Mobility Technologies 川鍋一朗氏×西内啓対談 Vol.2
西内啓の対談シリーズ。「Mobility Technologies」川鍋一朗さんの第2回目です。タクシー業界というレガシーな世界でデジタルシフトを実現するMobility Technologies。データという大きなアドバンテージを活用して、今後は新しいモビリティインフラへ進化を遂げたいと決意を話します。 シティズンデータサイエンスラボは「データサイエンスを全ての人に」を掲げる株式会社データビークル(https://www.dtvcl.com/)が運営する公式noteです。


「経験と勘」のタクシー営業がデジタルにシフトした Mobility Technologies 川鍋一朗氏×西内啓対談 Vol.1
データビークルの西内啓がデータ活用で成果をあげている組織のキーパーソンとデータサイエンスの現実について語り合う対談シリーズ。今回は、タクシー配車アプリ『GO』を展開する株式会社Mobility Technologiesならびに日本交通株式会社 代表取締役会長を務める川鍋一朗さんにお話を聞きました。(全2回) シティズンデータサイエンスラボは「データサイエンスを全ての人に」を掲げる株式会社データビークル(https://www.dtvcl.com/)が運営する公式noteです





マガジン
記事
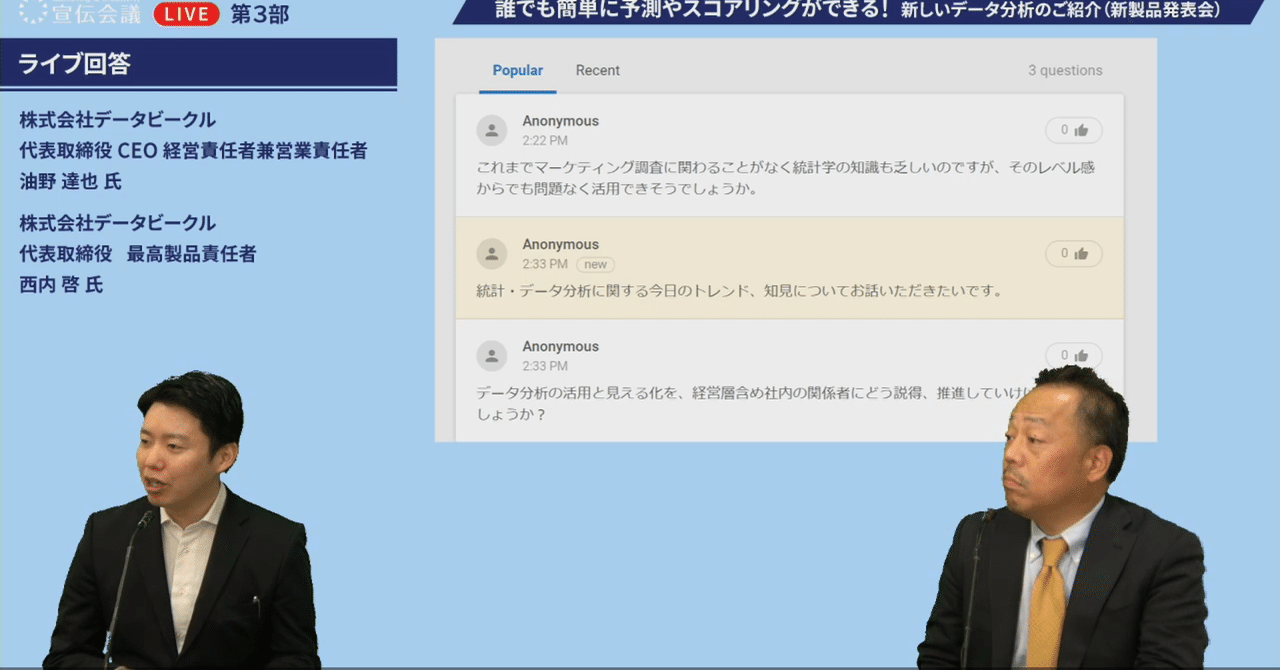
企業の意思決定のスピードをさらに加速するデータビークルの新製品「dataDiver TriA」オンライン発表会を開催しました!
2020年6月、データビークルは新商品「dataDiver TriA」(データダイバー トライア)を発表しました。dataDiverがこれまでご提供してまいりました「日本語によるわかりやすいデータ分析機能・予測機能」に加え、予測精度の検証機能、続けやすい料金体系など、データを使ってエビデンスにもとづく意思決定をしたいという企業にとって非常に魅力的な製品に仕上がっています。オンライン新製品発表会の様子をレポートします。 シティズンデータサイエンスラボは「データサイエンスを全て