
第1回 「活用できる状態のデータ」ってなんだろう

シティズンデータサイエンスラボは「データサイエンスを全ての人に」を掲げる株式会社データビークル(https://www.dtvcl.com/)が運営する公式noteです。
ないようであるデータ・あるようで使えないデータ
まずは、企業がデータを活用する際、最初のボトルネックとなりうる「データの問題」について考えていきたいと思います。
うちにはあまりデータなんてないと思っている企業でも実は意外にたくさんデータを持っています。一方で、うちは大量のビッグデータを持っていると思っている企業でも、いざ活用しようとするとそれだけでは使い物にならないことがわかったりします。なぜこのようなギャップが生まれてしまうのでしょうか?
その答えは「業務のためのデータ」と「活用のためのデータ」の違いにあります。
現代的な経営を行っているほとんどの企業は、業務を行えば必ずどこかにデータが蓄積されます。たとえば、あなたの会社の従業員について、どのような経歴の人間が、どのようなプロセスで採用され、その過程でどのような評価を受け、どの部署に配置され、いつ休んで、今までにいくらの賃金を受け取ったのかというデータを会社のどこかに持っているはずです。あるいは、工場で使う機械について、どのメーカーのどの型番のものを、いついくらで誰から調達し、どこに置いているか、というデータを持っている会社もあるでしょう。
このようなデータは、社内のITシステムの中に蓄積されたものもあれば、特定の部署だけで共有されるエクセルシートにのみ存在しているかもしれません。このような「業務のためのデータ」は、社内の情報を確認して管理する上で、あるいは社内外で必要な手続き( たとえば人事異動や給料の支払、減価償却の計算など)をする上で、誰かの記憶や紙に頼るよりもとても便利です。
ただ、業務のためのデータは「人が後から中身を見て確認できる」「エクセル上に該当箇所を読み込んで簡単な計算ができる」「特定の業務に用いられるシステムが止まらなければよい」というだけでその目的を達成できてしまいます。いざこのようなデータを活用しようとすると、そうした「業務のため」には十分だったはずのデータの問題点に気づくことになります。
活用のためのデータの基本構造
では「活用のためのデータ」とはどのようなものなのでしょうか?分析するにしても、AIに利用するにしても、活用のためのデータは基本的に次のような条件を満たしていなければいけません。
① 最終的には一枚の表にまとまっていなければいけない
② 最終的に用いられる項目は「数値の大小を示す」ものか「(せいぜい数十個程度の)有限な状態に分類する」もののみ
③ 行数は最低数十行以上
④ 列数は自由だが多ければ多いほど分析や予測の価値が増す
⑤ 中身のセルに抜け・漏れは基本的に許されない
この条件に当てはまらないものの一例に、業務用のデータベース内で、いくつもの表にまたがって管理されているデータや、フリーテキストで詳細な情報が記入されたデータなどを挙げることができます。こうしたデータはそのままでは活用できません。
具体例で考える活用のための加工法
この問題をもう少し具体的に掘り下げてみましょう。たとえば現在、世界中で営業するスーパーマーケットの多くはID-POS( 図表1-1)と呼ばれるシステムを導入しています。読者の皆様に、一度もスーパーマーケットでレジを打つところを見たことがないとか、ポイントカードという仕組みについてまったく想像がつかない、という人はいないでしょう。

それほど私たちの生活にとって身近な「業務のためのデータ」がスーパーマーケットのID-POSに蓄積されているわけですが、これを「活用のためのデータ」にしようとする場合、どのようなところに注目したらよいでしょうか?
まず条件①についてみると、多くの場合、ID-POSには少なくとも2種類の表が含まれていることが考えられます。1つは顧客マスター、つまり、ポイントカードを作ってくれた顧客1人につき1行、という形で、その中には氏名、性別や生年月日、住所といった個人情報が含まれます。一方、販売のトランザクションすなわち、レシートに印字される行ごとに、何の商品を、いつ、誰が、いくらで買ったのか、という形式の表で管理されるデータも存在します。これを購買のトランザクションまたは、購買履歴と呼びます。現代の業務システムでは多くの場合、リレーショナルデータベースが使われていますが、リレーショナルデータベースでは「顧客」と「購買」というように異なる粒度のデータを別々の表として管理することで、データ量を節約したり、整合性を取ったりしています。
ただし、別々の表とは言っても、多くの場合、レシート側のデータにおける「誰が」、というところは顧客1人ずつに振り分けられたIDで特定できるようになっています。したがって、丁寧に確認すれば表をまたいだ業務の処理、たとえば特定の顧客が昨日お買い物をしたかどうか、ということも理論上わかるようになっています。
しかし、このままの状態では顧客マスターと購買履歴は別々の表です。このままではデータ分析をするにしても単純な集計しかできませんし、AIのアルゴリズムを適用することもできません。
次に条件②について考えてみると、これらのデータの中には「数字の大小」と「( せいぜい数十個程度への)分類」ではない項目が多数含まれていることがわかります。たとえば顧客マスターは、性別は「( せいぜい数十個程度への)分類」ですが、氏名や住所には数十個よりはるかに数多くの種類があり、生年月日もそのままでは「数字の大小」というわけではありません。
レシート側の購買履歴についても、「いくらで」買ったかという項目は数字の大小ですが、「何の商品を」や「いつ」といった項目は、「数字の大小」でも「( せいぜい数十個程度への)分類」でもありません。
つまり、ID-POSデータで、そのまま使えるような項目はごくわずかで、「男女別にどちらの客単価が高いか」といった見える化ぐらいの活用しかできないということになります。
実際、私たちはこれまで、高額なシステムやツールを導入して大量のデータを蓄積しながら、この程度のわずかなデータ活用しかできていないという企業をたくさん目にしてきました。
データの規模が大きいということは最終的には、条件③である「行数の多さ」を満たしやすくなりますが、これは数十行~数万行あればそれ以上はデータ活用の価値を向上させるわけではありません。どれだけのビッグデータを集めたとしても、「数字の大小」、「有限な状態への分類」といった活用可能な列をたくさん用意できるかどうか、という条件④を満たせなければそれほど大した活用にはなりません。
有意義な分析結果を導き出すための2つの方法
このような「業務のためのデータ」と「活用のためのデータ」のギャップを克服するために、行なうべきことは大きく分けて、2つあります。( 図表1‒2)
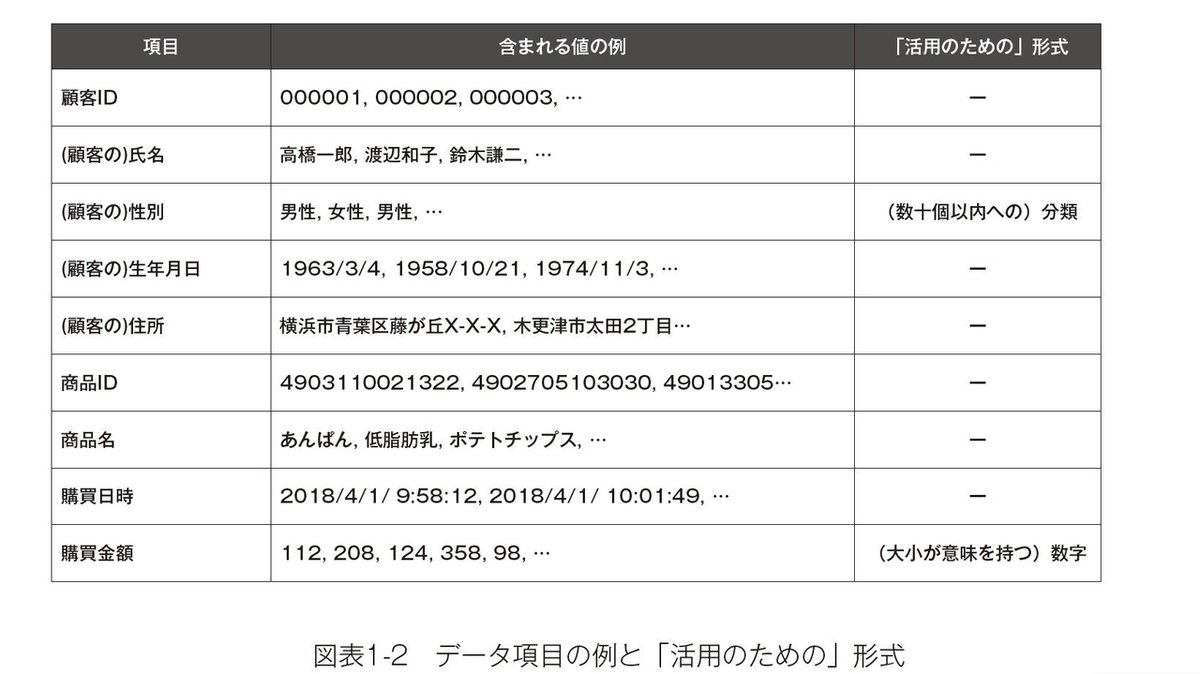
1つは「結合・集計」で、2つ目が「数値化と再分類」です。
「結合・集計」とはたとえば、エクセルのVLOOKUP関数とピボットテーブルを使ったり、SQLのJOIN句や集計関数を使ったりする操作などです。「顧客」と「購買」という、共通したID( 今回で言えば顧客ID)を使って2枚の表を紐づけ、その後もし「顧客ごと」という切り口で活用したければ、1人の顧客につき複数存在する購買履歴を集計して「1人の顧客に対して1行ずつ」という形のデータに加工します。こうした操作によって、条件①の問題はクリアできるはずです。
また、「数値化」とはたとえば生年月日や購買日時など、そのままでは大小を意味する数値ではない項目から、「年齢」や「直近の購買日からの経過日数」という数値を計算で示すことです。あるいは住所や商品名などそのままでは数十個をはるかに超える、フリーテキストのデータをうまく再分類して、「居住エリア」や「商品ジャンル」などの新たな項目を見出すこともできます。
データがキレイに管理されていれば、少しのコツがわかるだけでこうした作業はすぐに実行できます。しかし問題は、多くの企業の「業務のためのデータ」は、業務が円滑に回ることを目的としているため、結合や、数値化を阻む障壁が含まれている場合があります。
次回は、活用のための加工を阻む障壁も含めて、どのように作業を進めていくかを見ていきましょう。